
Thursday, February 27, 2020
View more at my Medium blog
For more posts on product development, product management and business strategy, please see my new Medium blog at:

Monday, August 17, 2015
Business Process – the missing element from Delve?
Microsoft Delve is an interesting new cloud product that attempts to bring together the many information sources a typical enterprise business user is interested in so that they can make sure they know what they need to.
It is often simplified to talk about finding people through content, or content through people.

Leaving aside the similarities with stalking work colleagues, it does seem to offer some value. One potential use case I heard of was finding all presentations presented to me in the last 12 months.
Delve is based around the Office Graph, which gathers data from across Office 365 and other tools (even eventually ones from ISVs). The idea seems simple enough:

The two relationship types they currently support are “Trending Around” (content related to a specific person) and “Working With” (people working with a specific piece of content). Graph edges are relationships and the nodes can be people or content (documents or conversations).
Clearly this could be very useful, but I think the missing element is business process.
Now traditionally we have represented the business process in a number of ways. perhaps it was the location (e.g. a Virtual File), a piece of metadata (e.g. project name), or just when it occurred (e.g. Collaborate 2015). These are all fairly imprecise, and one of the issues with business process as an idea is that you can have more than one present at a given moment in time.
For instance, this weekend I ended up paying $36 for internet access at the hotel my employer had our annual conference at. I am planning on expensing that amount on Monday. There are three business processes this involves:
In a graph we could add business process as another node, but that doesn’t involve it in the relationship between person and content the way we would want to. However, custom content types are going to be added soon, so the API would allow us to add a business process node easily enough. But would we link the piece of content, or the person to it?
We could make it an attribute of relationship, but that might limit our ability to query it (or not – see the idea of looking for content presented to me). Given there is a potential one-to-many relationship between a given edge (relationship) and business processes, it might requires changes to the Office Graph from Microsoft to give us that functionality.
There is another technical problem, which is how do we capture the relevant business processes that are involved in these person/content relationships? Do we ask users to act like lawyers and specify at every minute of the day what business processes they are involved in? Do we merely make them hashtags and allow people to tag everything they do, if they choose to do so? Is there some automated process that will prompt people to classify their content based on the meaning detected in the words they use?
Personally I think there is some real value in using hashtags – but they must be understood in the context of that person’s role, activities and context. So I might have tagged that expense reimbursement with these hashtags:
Those context variations to the hashtags require some rules, some intelligence, be applied to my hashtags in order to derive a better set of processes. That is hard, and that is where I would expect an app might want to call out to <handwave> (Cortana and the Office Graph?) to find info that would help solve the problem. We would also want other apps (CRM, ERP, etc) to support this sort of tagging, so their content could be properly understood as well. It sounds improbable, but interesting I think …
More info about the actions available as edges.
It is often simplified to talk about finding people through content, or content through people.

Leaving aside the similarities with stalking work colleagues, it does seem to offer some value. One potential use case I heard of was finding all presentations presented to me in the last 12 months.
Delve is based around the Office Graph, which gathers data from across Office 365 and other tools (even eventually ones from ISVs). The idea seems simple enough:
The two relationship types they currently support are “Trending Around” (content related to a specific person) and “Working With” (people working with a specific piece of content). Graph edges are relationships and the nodes can be people or content (documents or conversations).
Clearly this could be very useful, but I think the missing element is business process.
Now traditionally we have represented the business process in a number of ways. perhaps it was the location (e.g. a Virtual File), a piece of metadata (e.g. project name), or just when it occurred (e.g. Collaborate 2015). These are all fairly imprecise, and one of the issues with business process as an idea is that you can have more than one present at a given moment in time.
For instance, this weekend I ended up paying $36 for internet access at the hotel my employer had our annual conference at. I am planning on expensing that amount on Monday. There are three business processes this involves:
- The expense reimbursement business process.
- But the expense was only necessary because we were offsite at Activate 2015, so it was part of the Activate conference.
- The internet access was required because my flatmate at the time needed to upload a user research prototype for our Connect product.
In a graph we could add business process as another node, but that doesn’t involve it in the relationship between person and content the way we would want to. However, custom content types are going to be added soon, so the API would allow us to add a business process node easily enough. But would we link the piece of content, or the person to it?
We could make it an attribute of relationship, but that might limit our ability to query it (or not – see the idea of looking for content presented to me). Given there is a potential one-to-many relationship between a given edge (relationship) and business processes, it might requires changes to the Office Graph from Microsoft to give us that functionality.
There is another technical problem, which is how do we capture the relevant business processes that are involved in these person/content relationships? Do we ask users to act like lawyers and specify at every minute of the day what business processes they are involved in? Do we merely make them hashtags and allow people to tag everything they do, if they choose to do so? Is there some automated process that will prompt people to classify their content based on the meaning detected in the words they use?
Personally I think there is some real value in using hashtags – but they must be understood in the context of that person’s role, activities and context. So I might have tagged that expense reimbursement with these hashtags:
#expense #Activate2015 #ConnectUX
But they way those might be interpreted might vary by context. For example, #expense will be associated with the sort of expenses I am allowed – perhaps “discretionary travel expenses”. Further to that, #ConnectUX will be regarded due to the time period as relating to the Connect user experience research being conducted between the 10th and 21st of August.Those context variations to the hashtags require some rules, some intelligence, be applied to my hashtags in order to derive a better set of processes. That is hard, and that is where I would expect an app might want to call out to <handwave> (Cortana and the Office Graph?) to find info that would help solve the problem. We would also want other apps (CRM, ERP, etc) to support this sort of tagging, so their content could be properly understood as well. It sounds improbable, but interesting I think …
More info about the actions available as edges.
Tuesday, February 24, 2015
Stewardship vs Governance, is there a difference?
Early last year, Andrew White at Gartner asked the question When Information Governance and Stewardship Efforts Differ…do they?
He was dealing with the sort of grey line where two terms that almost equate to each other are used interchangeably or at least close to each other.
Information governance is something we concern ourselves a lot at Objective, so I was interested, and stewardship is something often talked about in Christian circles, so thinking about it in terms of information is also interesting.
Without just referencing online dictionaries/thesauri I would give the following definitions myself:
Update: I certainly don't think stewardship is '13 minutes a week' as this Gartner blog post suggests!
He was dealing with the sort of grey line where two terms that almost equate to each other are used interchangeably or at least close to each other.
Information governance is something we concern ourselves a lot at Objective, so I was interested, and stewardship is something often talked about in Christian circles, so thinking about it in terms of information is also interesting.
Without just referencing online dictionaries/thesauri I would give the following definitions myself:
Information Governance
Information governance is concerned with ensuring that we govern the way our organisation creates, consumes, collects and stores the information necessary to fulfil our purpose. It has connotations of restrictions, rules, compliance and auditing. It emphasises controls, policies and risk analysis.
Information StewardshipI think you could implement either of these concepts and find you were not doing the other. Both are desirable, but their emphasis is slightly different and they may indeed be two sides of the same coin. Perhaps it’s the classic dichotomy between cost and revenue, or pessimism and optimism at work.
Information stewardship is concerned with ensuring that we derive value from the information our organisation creates, consumes, collects and stores. It has connotations of exploitation, efficiency, profiting and judging. It emphasises usefulness, ease of access and valuation.
Update: I certainly don't think stewardship is '13 minutes a week' as this Gartner blog post suggests!
Wednesday, October 22, 2014
Evaporating Web Records
You’re hip, you’re cool – ‘business enablement’ is your middle name, and you’ve got social media accounts, blogs, forums, Atom/RSS feeds and wikis rocking and rolling. As Chief Records Officer (CRO) you help your agency move into the 21st Century full speed ahead.
Except. Things are never that easy, and what we find is web records are sadly missing.
We know that a short URL was used in this tweet, but 2 years later the URL has been re-used and no longer points where it did when we created the tweet. Worse yet, we relied on identifying records at creation and we missed one, it never got recorded and Facebook’s API is refusing to give it to us.
The wiki system was migrated to a new platform and the old edit history has been lost – worse the new system tracks comments in a different form and they have been lost too.
An ill-considered rollout of a new website neglected to ensure that all of our old URLs were migrated, and apart from losing Google ranking, we also now can’t identify what content a user might have seen on a given date for a given URL.
In other words, our web records are evaporating. It’s not your EDRMS that’s failing, it’s the fact that all of these web systems exist outside the EDRMS and compliance needs are seen as a secondary (unimportant?) requirement for replacement systems. Practical needs for delivering services now are overwhelming the old centralised compliance needs.
The “Review of Social Media and Defence” report in 2011 by George Patterson Y&R is a good example of the sorts of problems agencies face:
“Given the dynamic nature of social media communications and the collaborative approach to the creation of user generated content, Defence will need to take particular care to ensure that such content is properly identified as a Commonwealth record as and when it is created. An accurate and authentic copy of such content will need to be captured and saved as a record so as to ensure that obligations under the relevant auditing, recordkeeping and disclosure legislation can be met. This is likely to require the development of a specific Defence social media records policy that provides guidance for each particular social media channel to be used by Defence during Professional Use.”
Review of Social Media and Defence, p.102
“The simplest interpretation of international record-keeping policy is that all outgoing communication should be housed on an official website that provides both a credible source for the community and a method of archiving content. The content can then be shared easily into social media, and important or significant conversations can be selected for archiving.”
Review of Social Media and Defence, p.124
“Because the National Archives of Australia (NAA) considers social media to simply be channels in which Commonwealth records can be shared, existing record management and archiving protocols need to be followed. The challenge lies in identifying commonwealth records worthy of archiving but also in the resourcing and processes required to ensure compliance. The government’s response to the Government 2.0 Taskforce (p. 15) states explicitly that the Archives will produce guidance on what constitutes a Commonwealth record in the context of social media. The NAA should be consulted to provide greater clarification for DEOC.”
Review of Social Media and Defence, p.157
Rebecca Stoks produced an academic paper in October 2012 that summarised a survey of actual recordkeeping practices for social media records amongst Australian government agencies (mostly state (33), but some local (20) and federal(9) agencies). Her summary was damning:
“The transient nature of social media opposes traditional recordkeeping methods; consequently, most government agencies are not meeting their legal obligation to keep records.”
“In this study, only a minority of government agencies were found to be capturing social media records. Most of those capturing records were not very confident that they are meeting their legal obligations or that their methods are sustainable. Within the sample, the level of internal support, be it strong or lacking, was found to affect the degree to which social media records were being captured. Although well regarded as a resource, the guidance provided by PROs did not seem to have an impact on whether or how agencies were capturing records, with several respondents expressing a desire for more practical advice.”
Taming the Wild West: Capturing Public Records Created on Social Media Websites, p.8
Taming the Wild West: Capturing Public Records Created on Social Media Websites, p.48
What do we want to know about web records when we capture them?
- URL
- AGLS meta-data (author, publish date/time, country, copyright, etc)
- Re-use (trackbacks, retweets, inbound links, ratings, likes, votes)
- Outbound links, and their status (if they redirect, then to what URL? do they have meta-tags set like NoFollow?)
- Linked resources (images, JavaScript, iframes, Flash files, video/audio) – not always useful, but worth bringing images into content as an embedded image at very least
- Conversations started by the record (comments, replies, threads in general)
- Relative site-map location compared to other web records (requires the concept of a site, perhaps leverage Google site maps?)
Much of this comes from Atom/RSS feeds, but some of it requires post-capture processing.
How do we want to see web records that we capture?
- As an HTML page, even though stored as XML.
- As a PDF, even though originally seen as an HTML page and stored as XML.
Of course this only gets us 80% of what we need, there will always be the missing context of what the page design looked like when that content was displayed (and what other content was dynamically displayed alongside it). With social media there is also the context of an responses, retweets, likes, shares or trackbacks to consider.
Do we organise web records by the site they belong to, the Atom/RSS feed they come from, or by some other more definite measure?
I don’t know anyone that has all the answers to those questions, I’m not even sure I know that many people that care about all those questions! However, I do know that without those answers there are essential government records that are literally evaporating every minute of the day, never to be seen again, or known about. They may not be important now, they may not ever be important, but our lack of care with them is likely to be lamented by future generations seeking to understand what motivated, inspired and drove us into action (or not).
Tuesday, October 21, 2014
Collaborate 2014 Roundup
We just finished another Collaborate conference for Objective Corp's international customers and it was a great effort by all; staff, partners and customers included.
The amount of effort that goes into the event is extraordinary, but the payoff is an event that informs, excites and inspires our customers to get more value from their Objective products (ECM, ECC and Connect) and change the way their organisations impact the world.
A big part of that is helping them drive business process innovation so they can deliver better services and products to the public.

Something we are doing across our products is looking to deliver great user experiences, especially ones that are customised for our customers' organisations so that they are received by their end users with credibility.
One of the challenges that raises is what an old colleague of mine used to call the "pink flamingo effect":

This is the tendency of some people to go wild with any sort of HTML customisation and add what they assume is an attractive element (e.g. pink flamingos) to an otherwise functional page.
We can't prevent that altogether, but a big part of the move we're making is to educate customers about the sorts of things they should consider customising (logos, fonts, colours) and how to consider the user experience when customising things that we have carefully designed, such as our responsively designed sample email templates.
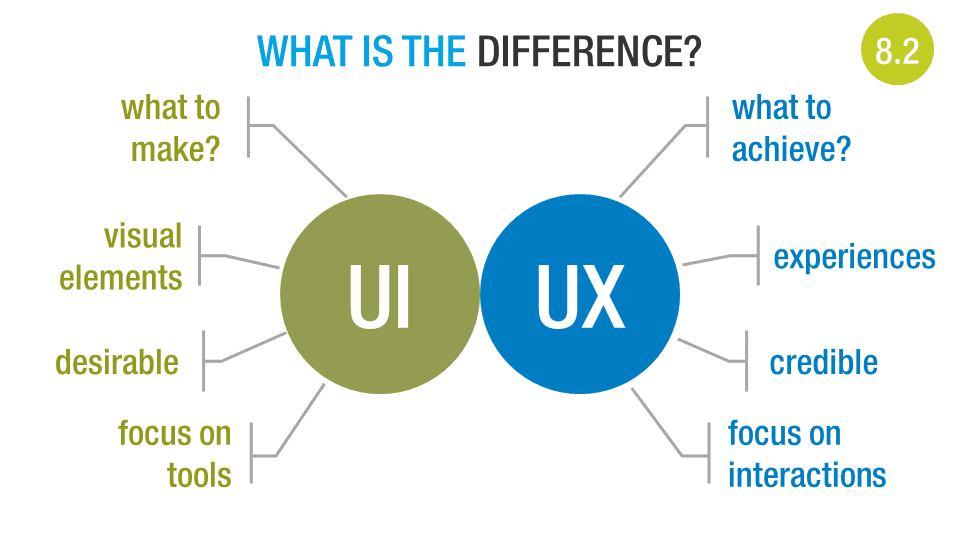
To that end the slide above was used to help explain the difference between user interfaces (UI) and user experiences (UX).
Edit: See more about UI vs UX at my colleague David Eade's blog.
The amount of effort that goes into the event is extraordinary, but the payoff is an event that informs, excites and inspires our customers to get more value from their Objective products (ECM, ECC and Connect) and change the way their organisations impact the world.
A big part of that is helping them drive business process innovation so they can deliver better services and products to the public.
Something we are doing across our products is looking to deliver great user experiences, especially ones that are customised for our customers' organisations so that they are received by their end users with credibility.
One of the challenges that raises is what an old colleague of mine used to call the "pink flamingo effect":
This is the tendency of some people to go wild with any sort of HTML customisation and add what they assume is an attractive element (e.g. pink flamingos) to an otherwise functional page.
We can't prevent that altogether, but a big part of the move we're making is to educate customers about the sorts of things they should consider customising (logos, fonts, colours) and how to consider the user experience when customising things that we have carefully designed, such as our responsively designed sample email templates.
To that end the slide above was used to help explain the difference between user interfaces (UI) and user experiences (UX).
Edit: See more about UI vs UX at my colleague David Eade's blog.
Updated blog template
It's been a few years since I updated the template my blog uses, so I've taken the chance now to simplify things and apply a template that seems less busy and more modern. I've also updated the fonts to make them more readable on modern screens.
Friday, January 18, 2013
You need consumer-grade usability
It’s interesting watching the English language evolve in response to technology and changing cultural ideas. Take the term “consumer-grade”, this used to (and sometimes still does) mean, lower quality, less robust construction.
Compare it to “weapons-grade”, a term commonly applied to uranium and plutonium, but simply meaning it is a substance pure enough to to be used to make a weapon or has properties that make it suitable for weapons use. “Export-grade” is similarly used to define food or beverage that is better than average, and worthy of consumption away from its place of production. Some people seem to confuse the two.
")
So you might be confused by someone espousing “consumer-grade usability” as a good thing … confused that is, if you lived in 1999 and knew nothing about the history of consumer devices in the 21st century … you know, the whole iPod, iPhone, iPad, Alienware, LCD televisions, Android and “just google it” thing?
Now that we are living in an increasingly BYOD world it is obvious what the term means. It is a purity of user interface design that brings the essential features of the device or application to the fore, and frees anyone to use it with confidence and passion.
It’s easy to see how this came about, “consumers” includes everyone, “enterprise users” are a small subset of the working population, itself a subset. When creating for the consumer it has become obvious that success increasingly comes from great usability – even when competing in the budget end of the market. This means everyone gives usability lip-service, hence the rise in usability consultancies.
Consumers have access to free tools that are developed with such care that they make the average enterprise application look clunky in comparison – and they are beginning to get sick of it!!
The challenge as I see it is how do I as an enterprise product manager bring consumer-grade usability to my products, without making people see it as just a gimmick, or a band-aid fix?
Update: The Consumerization Revisited – Why Aesthetics Matter article from QlikTech points out that aesthetics matter when it comes to usability and user adoption.
Subscribe to:
Comments (Atom)